Intel收購Nervana的目標在於取得其預計2017年問世的深度學習加速器晶片,如果該晶片的性能表現如預期,Intel的深度學習加速器硬體開發板可望…
處理器大廠英特爾(Intel)將於下週於美國舊金山舉行的Intel Developer Forum (IDF)年度開發者論壇,進一步闡述該公司收購深度學習(deep learning)技術供應商Nervana Systems的意圖──此舉被視為Intel與深度學習人工智慧(AI)應用繪圖處理器(GPU)競爭的重要策略。
Intel在高性能運算(high-performance computing,HPC)市場居主導地位,Nvidia則以其複雜GPU在深度學習領域有大幅進展;而Nervana Systems的GPU則是以相容於Nvidia的Cuda軟體與自家Neon雲端服務在市場獲得關注。
Intel收購Nervana的目標在於取得其預計2017年問世的深度學習加速器晶片,如果該晶片的性能表現如預期,Intel的深度學習加速器硬體開發板可望超越Nvidia的GPU開發板,同時收購自Nervana的Neon雲端服務之性能表現也將超越Nvidia的Cuda軟體,

Intel執行副總裁暨資料中心事業群總經理Diane Bryant與Nervana共同創辦人Naveen Rao
(來源:Intel)
「這並Intel給Nvidia的一記重擊,」市場研究機構Moor Insights & Strategy的深度學習暨高性能運算資深分析師Karl Freund接受EE Times訪問時表示:「但這是進軍一個成長非常快速的市場之合理策略。」
Freund進一步解釋:「GPU是訓練深度學習神經網路的一個熱門方法,Nvidia在該領域是領導廠商;Intel則有自己的多核心Xeon/ Xeon Phi處理器,以及收購自Altera的FPGA,卻沒有GPU。收購Nervana是以一個非複製通用GPU策略進軍深度學習市場的方法,也就是透過提供為神經網路量身打造的特製處理器。」
Nervana運算速度號稱可達每秒8 terabit的Engine晶片,是一款以矽中介層(silicon-interposer)為基礎的多晶片模組,配備terabyte等級的3D記憶體,環繞著3D花托狀架構(torus fabric)、採用低精度浮點運算單元(FPU)的連結神經元;因此Freund指出,該晶片與競爭通用GPU相較,能以更小的尺寸支援每秒更多次數的深度學習運算,
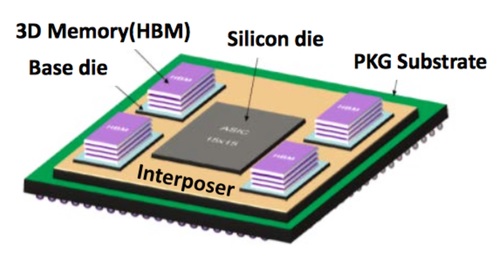
Nervana 的Engine晶片架構
(來源:Nervana)
Freund表示:「深度學習神經網路能擺脫通用GPU在理論上過度誇大的較低精度運算;雖然Nervana的晶片要到明年才問世、因此目前並沒有公布任何性能量測基準資料,但為深度學習神經網路量身打造的特殊應用晶片,性能應該會超越在通用GPU的相同演算法。」
Intel聲稱,目前全世界有97%支援機器學習的伺服器都是採用Xeon/Xeon Phi晶片,但這些伺服器佔據全球伺服器的比例不到10%;不過Intel也表示,機器學習是成長速度最快的AI應用,因此該公司準備好以Nervana的Engine晶片為基礎的深度學習神經網路,找回因GPU競爭而流失的市佔率。
針對Nervana的收購,Intel執行副總裁暨資料中心事業群總經理Diane Bryant在一篇部落格文章中表示:「人工智慧正在轉變商業運作以及人們參與世界的模式,而它的子集──深度學習,是擴展AI領域的關鍵方法。」
據了解,Intel將把Nervana的演算法納入Math Kernel Library,以與其產業標準架構整合;此外收購Nervana將讓Intel取得Neon雲端服務,因此為旗下的雲端服務增加支援Nvidia深度學習技術的產品。
Freund表示,Nvidia若要維持競爭力,可能也需要以低精度特製深度學習處理器來回應Intel+Nervana。目前Nervana的團隊有48位工程師與管理階層,將歸入Bryant負責的Intel資料中心事業群(Data Center Group)。
編譯:Judith Cheng
(參考原文: Intel to Acquire Deep Learning Nervana,by R. Colin Johnson)
資料來源:電子工程專輯


 留言列表
留言列表